
- Dịch vụ chạy mô hình và phân tích dữ liệu với SPSS, EVIEWS, STATA, R, AMOS
- Dịch vụ chạy SPSS thuê | Phân tích thuê SPSS
- Dịch vụ nghiên cứu, phân tích định lượng trong kinh tế, quản trị, phân dữ liệu định lượng, nhân tố khám phá EFA, phân tích nhân tố trong SPSS
- Xử lý số liệu với SPSS, EVIEWS
- Dịch vụ phân tích dữ liệu- Hỗ trợ báo cáo, hoàn thiện luận văn
Topic này sẽ giới thiệu cách sử dụng phần mềm IBM cognos SPSS Statistics Standard 20.0 cho các phân tích dự báo căn bản dùng trong các nghiên cứu chuyên sâu hoặc sử dụng cho mục đích nghiên cứu thị trường, nghiên cứu hành vi khách hàng và hướng dẫn cách đọc kết quả dữ liệu phân tích thông qua các chỉ số, mô hình hồi quy...
Các bước phân tích cơ bản dành cho các nghiên cứu chuyên sâu như sau:
Lưu ý: Với các phân tích cơ bản này, đòi hỏi người dùng đã có dữ liệu lịch sử nghiên cứu, đã kiểm tra, làm sạch trước khi sử dụng cho các các bước phân tích này
- Kiểm định độ tin cậy Cronbach's Alpha
- Phân tích nhân tố EFA
- Phân tích tượng quan
- Phân tích hồi quy
- Phân tích ANOVA
- Thống kê mô tả, tần số
Kịch bản dùng demo như sau:
Phân tích các yếu tố ảnh hưởng đến ý định mua hàng của người dùng trực tuyến tại TPHCM.
Mô hình phân tích như sau:
Sau khi thu thập dữ liệu với các thang đo kết quả cho từng nhân tố với thang đo từ hoàn toàn không đồng ý đến hoàn toàn đồng ý được mã hóa từ 1-5, tác giả nhập vào data vào tab Variable View.
Last edited by a moderator: Aug 19, 2014
LeHuyenTrang_170288, tableau, Hiền and 2 others like this
Hệ số Cronchach's Alpha là 1 phép kiểm định thống kê dùng kiểm tra sự chặt chẽ và tương quan giữa các biến quan sát
- Kiểm định độ tin cậy Cronbach's Alpha
Theo đó , những biến có hệ số tương quan tổng phù hợp (Corrected Item - Total Correclation) lớn hơn 0.3 và có hệ số Alpha lớn hơn 0.6 mới xem là chấp nhận được và thích hợp đưa vào các bước phân tích tiếp theo. Cũng như nhiều nhà nghiên cứu, nếu Cronbach's Alpha đạt từ 0.8 trở lên thì thang đo lường tốt và mức độ tương quan sẽ cao hơn.
Thao tác:
- B1: Analyze/Scale/Reliability Analysis...

- B2: Nhấp chọn các thang đo thuộc 1 nhân tố,đặt tên label hiển thị.

- B3: Nhấp ô Statistics, chọn Scales If item delected/ Nhấp continue
Đọc kết quả hiển thị:
- Hệ số Anpha của biến nhận thức giá = 0.698 : chấp nhận được và tiếp tục đưa vào phân tích tiếp.
- Hệ số tương quan tổng > 0.3
- Hệ số tượng quan tổng khi loại thang đo đều thấp hơn hệ số Apha: phù hợp để chọn tất cả các thang đo

Last edited by a moderator: Aug 19, 2014
Phân tích nhân tố khám phá là một phương pháp phân tích thống kê dùng để rút gọn một tập gồm nhiều biến quan sát phụ thuộc lẫn nhau thành một tập biến (gọi là các nhân tố) ít hơn để chúng có ý nghĩa hơn nhưng vẫn chứa đựng hầu hết nội dung thông tin của tập biến ban đầu.
- Phân tích nhân tố EFA
Khi phân tích nhân tố có một số điểm cần lưu ý như sau:
Thao tác:
- Thứ nhất, hệ số tải nhân tố (Factor loading): là hệ số tương quan đơn giữa các biến và nhân tố, là chỉ tiêu để đảm bảo mức ý nghĩa thiết thực của EFA. Hệ số tải nhân tố > 0,3 được xem là đạt được mức tối thiểu, hệ số tải nhân tố > 0,4 được xem là quan trọng, > 0,5 được xem là có ý nghĩa thực tiễn. Nếu chọn tiêu chuẩn hệ số tải nhân tố > 0.3 thì cỡ mẫu ít nhất phải là 350, nếu cỡ mẫu khoảng 100 thì nên chọn tiêu chuẩn hệ số tải nhân tố > 0.55, nếu cỡ mẫu khoảng 50 thì hệ số tải nhân tố phải > 0.75. Cho nên, nếu biến quan sát nào có hệ số tải nhân tố < 0.55 sẽ bị loại.
- Thứ hai, hệ số KMO (Kaiser-Meyer-Olkin) là một chỉ tiêu dùng để xem xét sự thích hợp của EFA, 0,5 ≤ KMO ≤ 1 thì phân tích nhân tố là thích hợp. Kiểm định Bartlett xem xét giả thuyết Ho: độ tương quan giữa các biến quan sát bằng không trong tổng thể. Nếu kiểm định này có ý nghĩa thống kê (Sig ≤ 0,05) thì các biến quan sát có tương quan với nhau trong tổng thể.
- Thứ ba, thang đo được chấp nhận khi tổng phương sai trích ≥ 50%.
- Thứ tư, số lượng nhân tố được xác định dựa vào hệ số Eigenvalue đại diện cho phần biến thiên được giải thích bởi mỗi nhân tố, hệ số này phải có giá trị ≥ 1.
- Thứ năm, khác biệt về hệ số tải nhân tố của một biến quan sát giữa các nhân tố ≥ 0,30 để đảm bảo giá trị phân biệt giữa các nhân tố.
- B1: Analyze/ Data Reduction/Factor: Chọn tất cả các biến cần gom nhóm vào ô Variables.

- B2: Click chọn ô Descriptives/ Chọn các tham số như hình dưới

- B3: Click chọn ô Rotation (Xoay nhân tố) để mở hộp thoại sau:
(Xoay nhân tố là thủ tục giúp ma trận nhân tố trở nên đơn giản và dễ giải thích hơn)
- B4: Nhấp chọn Option, điền tiêu chuẩn hệ số tải nhân, với kịch bản như trên, tác giả chỉ khảo sát với 241 mẫu, nên chọn hệ số tải nhân >0.55
Đọc kết quả phân tích EFA:
- Kết quả phân tích nhân tố (EFA) cho thấy 17 biến quan sát được nhóm thành 5 nhân tố. Hệ số tải nhân tố (Factor Loading) đều > 0.55 nên các biến quan sát đều quan trọng trong các nhân tố, chúng có ý nghĩa thiết thực. Mỗi biến quan sát có sai biệt về hệ số tải nhân tố đều ≥ 0.30 nên đảm bảo được sự phân biệt giữa các nhân tố. Hệ số KMO = 0.734 nên EFA phù hợp với dữ liệu. Thống kê Chi-square của kiểm định Bartlett’s đạt giá trị mức ý nghĩa là 0,000. Do vậy các biến quan sát có tương quan với nhau xét trên phạm vi tổng thể.

- Phương sai trích đạt 69.211% (>50%) thể hiện rằng 5 nhân tố rút ra giải thích được 69,211% biến thiên của dữ liệu; do vậy các thang đo rút ra được chấp nhận. Điểm dừng khi rút trích nhân tố thứ năm với eigenvalue = 1,240 đạt yêu cầu.

LeHuyenTrang_170288, Hiền, tableau and 2 others like this.

Các thang đo được đánh giá đạ yêu cầu được đưa vào phân tích tương quan Pearson và phân tích hồi quy để kiểm định các giả thuyết. Phân tích tượng quan Person được thực hiện giữa các biến phụ thuộc và các biến độc lập, khi đó việc sử dụng phân tích hồi quy tuyến tính là phù hợp. Giá trị tuyệt đối của Pearson càng gần đến 1 thì hai biến này có mối tương quan tuyến tính càng chặt chẽ. Đồng thời cũng cần phân tích tương quan giữa các biến độc lập. Vì những tương quan như vậy có thể ảnh hưởng lớn đến kết quả của phân tích hồi quy như gây ra hiện tượng đa công tuyến.
- Phân tích tương quan
Thao tác:
- B1: Analyze/Scale/Correlate/Bivariate...Chọn các nhân tố trung bình đại diện cho thang đo vào ô Variable

- Đọc kết quả tương quan:
- Các biến độc lập đều có tương quan tuyến tính khá mạnh với biến phụ thuộc, các hệ số tương quan đều có ý nghĩa thống kê (p < 0.01).
- Cụ thể, mối quan hệ tương quan giữa biến ý định mua (Int) và nhận thức giá (Price) là 0.441, tương quan với niềm tin (Trust) là 0.469, tương quan với nhận thức sự dễ sử dụng (Conv) là 0.494, tương quan với ảnh hưởng xã hội (Ref) là 0.393, tương quan với kinh nghiệm là 0.490.
- Như vậy, việc sử dụng phân tích hồi quy tuyến tính là phù hợp. Tuy nhiên, kết quả phân tích tương quan cũng cho thấy hệ số tương quan giữa các biến độc lập ở mức tương quan mạnh nên cần quan tâm đến hiện tượng đa cộng tuyến khi phân tích hồi quy đa biến.

Hiền likes this.
Quá trình kiểm định giả thuyết được thực hiện theo các bước sau:
- Phân tích hồi quy
Thao tác:
- Đánh giá độ tin cậy phù hợp của mô hình hồi quy đa biến thông qua R2 và R2 hiệu chỉnh.
- Kiểm định giả thuyết vầ độ phù hợp của mô hình
- Kiểm định giả thuyết về ý nghĩa của hệ số hồi quy từng thành phần
- Kiểm định giả thuyết về phân phối chuẩn của phần dư : dựa theo biểu đồ tần số dư chuẩn hóa; xem giá trị trung bình bằng 0 và độ lệch chuẩn bằng 1.
- Kiểm định giả định về hiện tượng đa cộng tuyến thông qua giá trị của dung sai (Tolerance) hoặc hệ số phóng đại phương sai VIF (Variance Inflation Factor). Nếu VIF >10 thì có hiện tượng đa cộng tuyến
- Xác định mức độ ảnh hưởng của các yếu tố: hệ số beta của yếu tố nào càng lớn thì có thể nhận xét yếu tố đó có mức độ ảnh hưởng cao hơn các yếu tố khác trong mô hình nghiên cứu.
- B1: Analyze/ Regression/Liner

- B2: Nhấp Statistics, nhấp chọn biến phụ thuộc vào ô Dependent, chọn biến độc lập vào ô Independent

- B3: Nhấp Plots, chọn ô Conllinearity diagnostics để kiềm tra hiện tượng cộng tuyến.

- B4: Nhấp chọn Save, vẽ mô hình hiển thị bộ dữ liệu với cột X, Y tương ứng như hình vẽ

4 biến độc lập Price, Trust, Conv, Ref, Exp có hệ số beta chuẩn hóa là Price = 0.195; Trust = 0.233; Conv = 0.171, Ref = 0.110 và Exp = 0.372, với mức ý nghĩa nhỏ hơn 0,05. Các hệ số này cho thấy tầm quan trọng tương đối của các biến độc lập Price, Trust, Conv, Ref, Exp khi chúng cùng một lúc được đưa vào mô hình giải thích cho biến phụ thuộc Int. Hệ số tương quan từng phần dao động từ 0,042 đến 0,386 góp phần làm hiểu rõ hơn tầm quan trọng của từng biến khi chúng được sử dụng chung với các biến khác trong mô hình. Như vậy, hệ số beta chuẩn hóa và hệ số tương quan từng phần cho thấy mức độ quan trọng của các biến ảnh hưởng tới ý định mua (Int) theo thứ tự sau: thứ nhất là kinh nghiệm (Exp), thứ hai là niềm tin (Trust), thứ ba là nhận thức giá (Price), thứ tư là nhận thức sự tiện dụng (Conv), thứ năm là ảnh hưởng xã hội (Ref).
- Đọc kết quả hồi quy:
Như vậy, dựa theo kết quả nghiên cứu, tác giả có thể đưa ra 1 số đóng góp quản trị như sau:
Phương trình hồi quy: Int = 0.372Exp + 0.233Trust + 0.195Price + 0.171Conv + 0.110Ref
- Tận dụng kinh nghiệm online của khách hàng phát triển chiến lược kinh doanh số
- Xây dựng niềm tin của khách hàng về chất lượng, cam kết, dịch vụ...
- Tận dụng lợi thế về giá: giá thấp
- Phát triển các đặc tính tiện dụng
- Khai thác sức mạnh ảnh hưởng xã hội.
Last edited by a moderator: Aug 21, 2014
Dùng trong việc kiểm định sự khác biệt giữa các biến định tính
- Phân tích ANOVA
Trong trường hợp biến phân loại có từ 3 nhóm trở lên ta tiến hành phân tích phương sai một yếu tố (One-Way ANOVA), với giả thuyết Ho là không có sự khác biệt giữa các nhóm, nếu kết quả kiểm định có mức ý nghĩa quan sát nhỏ hơn 0.05 ta bác bỏ giả thuyết Ho. Kết quả của việc bác bỏ hay chấp nhận Ho sẽ ảnh hưởng đến việc lựa chọn tiếp thủ tục kiểm định nhằm tìm xem sự khác biệt giữa các nhóm xảy ra ở đâu.Thao tác:
- B1: Analyze/ Compare Means/ One-Way ANOVA

- B2: Chon nhân tố để kiểm định sự khác biệt.

- B3: Nhấp chọn Option: chọn như hình vẽ để hiền thị bảng thống kê và bảng test Homogenity

Phương sai trong kiểm tra tính đồng nhất (Homogeneity test) của thành phần Int là 0.257 lớn hơn 5%, cho biết phương sai của các nhóm tuổi là bằng nhau, thỏa điều kiện phân tích ANOVA
- Đọc kết quả phân tích ANOVA
Trong bảng phân tích ANOVA, ta nhận thấy có sự khác biệt về độ tuổi của khách hàng đối với ý định mua vì trong bảng kết quả phân tích ANOVA Sig.= 0.025 < 0.05: Bác bỏ giả thuyết Ho
Như vậy, kiểm định theo độ tuổi của khách hàng cho thấy có sự khác biệt trong ý định mua hàng trực tuyến
Tiếp tục phân tích sâu ANOVA bằng kiểm định Bonferroni để tìm xem sự khác biệt về ý định mua hàng giữa các nhóm tuổi, nhận thấy có sự khác biệt giữa các nhóm tuổi sau: nhóm <25t với nhóm >35t, nhóm 25-35t và nhóm >35t, không có sự khác biệt giữa nhóm <25t với nhóm 25-35t.
Link http://forums.bsdinsight.com/threads/spss-statistics-standard-20-0.3648/
Dưới đây là quy trình của một cuộc nghiên cứu, bất luận lĩnh vực- quy mô thì nó cũng trải qua đầy đủ các bước
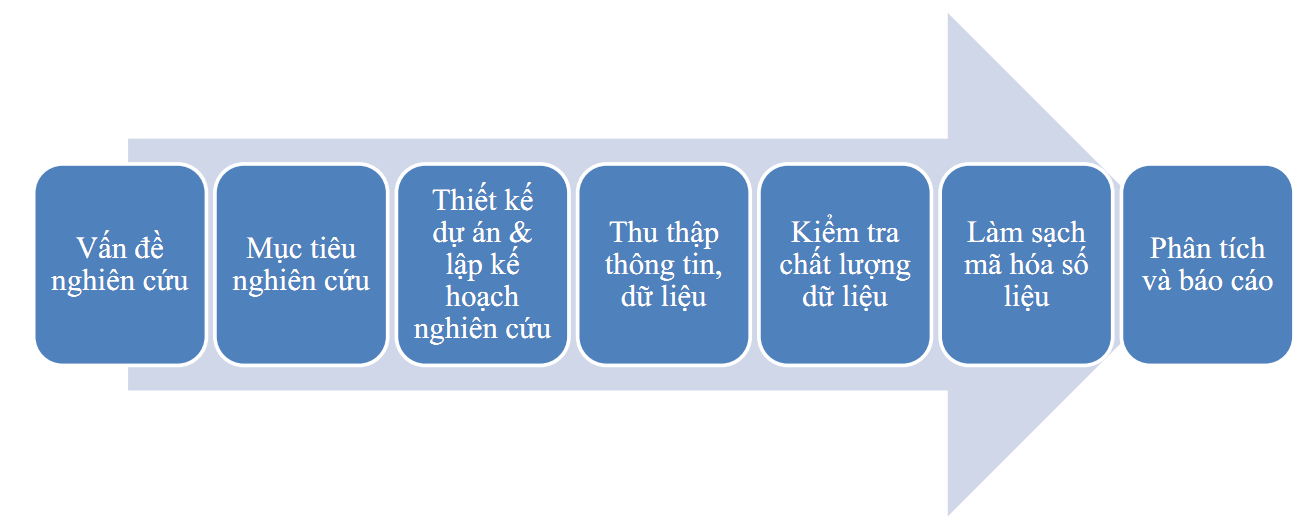
- B1: Xác định vấn đề nghiên cứu
- B2: Xác định mục tiêu nghiên cứu
- B3: Thiết kế dự án- lập kế hoạch
- B4: Thu thập dữ liệu
- B5: Kiểm tra
- B6: làm sạch, mã hóa
- B7: Phân tích, báo cáo
Trong trường hợp cần chúng tôi hỗ trợ 01 hay nhiều công đoạn- để tạo điều kiện thuận lợi nhất vui lòng gửi toàn bộ các tài liệu liên quan tới các công đoạn trước cho chúng tôi.
***********************************
Các bạn đang xem bài viết tại website XỦ LÝ SỐ LIỆU- Một dịch vụ của
Antsmrg
ANTS là nhóm chuyên cung cấp dịch vụ nghiên cứu xã hội- thị trường cho các tổ chức và các nhân ở mọi quy mô. Các dịch vụ của chúng tôi bao gồm
- Tư vấn, thiết kế nghiên cứu
- Thiết kế bảng hỏi, thu thập số liệu
- Phân tích, báo cáo
Đối với dịch vụ XỬ LÝ SỐ LIỆU, chúng tôi cung cấp các gói dịch vụ liên quan
- Tư vấn, xây dựng mô hình, chạy các phần mềm thống kê thích hợp hoặc theo yêu cầu:SPSS, EVIEWS, STATA, R, AMOS,...
- Tổng hợp, báo cáo, đề xuất sau phân tích
- Tư vấn, hoàn thiện luận văn tốt nghiệp, cao học,... theo yêu cầu
Mọi yêu cầu, thắc mắc vui lòng gửi lại thông tin cho chúng tôi tại mục "Liên hệ với chúng tôi" tại cuối website này.
+++++++++++++++++++++++++++++++



